Wie Du KNIME direkt mit dem Screaming Frog verbindest (Teil 2)
Effektive Verbindung zwischen KNIME und Screaming Frog: Erfahre, wie du mithilfe des Derby-Treibers eine Datenbankverbindung herstellst, Crawldaten abfragst und deine Analyseverfahren optimierst – Praxisnaher Leitfaden.
In meinem Wingmen-Newsletter-Artikel “Direkter Frosch-Zugriff mit KNIME (Teil 1)” hatte ich Dir schon die Grundlagen für diese Verbindungen beschrieben. Leider kommen berufliche Veränderungen dann doch schneller als gedacht und Newsletter-Artikel werden nicht rechtzeitig fertig. Ich möchte Dir den Inhalt von “Teil 2” jedoch nicht vorenthalten und veröffentliche ihn daher als Blog-Artikel.
In Teil 1 haben wir die Grundlagen für eine erfolgreiche Verbindung zur Datenbank des Screaming Frogs geschaffen und uns in Derby die Datenbankstruktur eines Crawls angeschaut. Für alle, die diesen Schritt noch nicht durchgeführt, habe ich hier eine tolle Nachricht: Die Installation ist noch einfacher geworden. Über das Script sfadmin.php kannst Du nun auch den benötigten Derby-Datenbank-Treiber ganz einfach über ein Kommando herunterladen und in KNIME installieren.
Update: Das Script sfadmin.php wird nun langsam erwachsen. Ab sofort gibt es den Screaming Frog Admin auch als Anwendung (DMG-Installation) für den Mac. Die Windows-Version ist schon in Arbeit.
Voraussetzungen
Um den Screaming Frog mit KNIME verbinden zu können bzw. um direkt auf die Daten eines Crawls zugreifen zu können, sind wenige Voraussetzungen nötig. Diese sind jedoch zwingend erforderlich:
- Ein lizenzierter Screaming Frog
- Der Screaming Frog muss im “Database Storage” Modus betrieben werden
- Du solltest Dich mit KNIME schon etwas auskennen. Die grundlegenden Funktionsweisen wie Du Workflows anlegst, Nodes findest und hinzufügst, werden in diesem Artikel nicht erklärt.
Das Tool sfadmin.php prüft die technischen Voraussetzungen und gibt Dir benötigte Hinweise, wenn die Voraussetzungen in Deinem System nicht stimmen sollten.
Screaming Frog & KNIME verbinden
Dazu müssen wir jetzt den Derby-Treiber auch in KNIME installieren und in KNIME bekannt machen. Dies können wir manuell über viele umständliche Schritte tun oder unser Tool sfadmin.php nutzen. Dies rufen wir wieder über ein Terminal- / Command-Fenster auf:
- Beende KNIME vollständig
- Aufruf des Tools
> php sfadmin.php - Installation des Treibers
> install derby
Folge den Anweisungen, bis Du wieder im Hauptmenü des Tools angekommen bist. - Beende sfadmin.php
> quit - Starte KNIME erneut
Mit diesem Prozess haben wir den aktuellen Derby-Treiber auch schon heruntergeladen und in KNIME installiert.
Benötigte KNIME-Nodes
Als Erstes benötigen wir einen “DB Connector”. Mit diesem wird die eigentliche Verbindung hergestellt. Wir müssen ihm aber noch sagen, mit welcher Art von Datenbank (derby) wir uns verbinden wollen und wo die Datenbank zu finden ist.
Dies tun wir, indem wir mit einem Doppelklick auf das Node oder über das Kontextmenü “Configure…”, die Konfiguration des Nodes aufrufen:
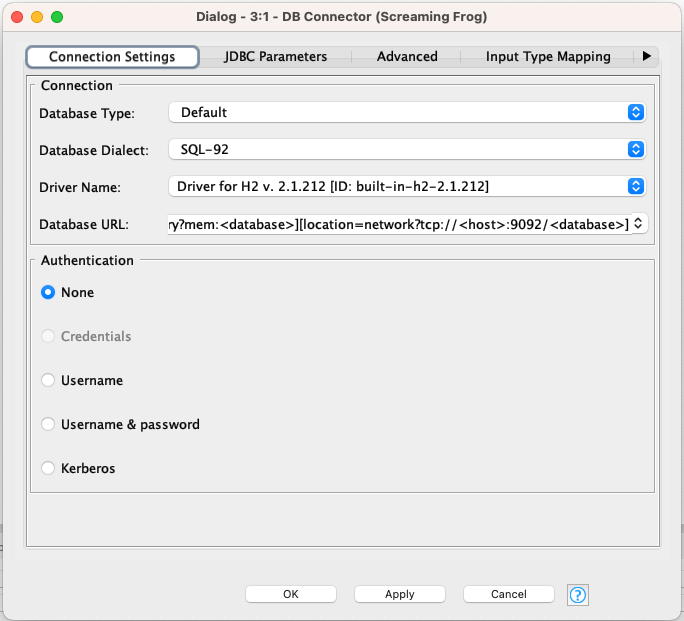
Festlegen des Datenbanktypes
Dazu müssen wir unter “Driver Name” “derby [ID: derby]” auswählen. (Dieser Eintrag wurde durch unser Tool sfadmin.php im ersten Schritt neu angelegt).
Ermittlung und Festlegung der Database URL
Die Database URL ist sozusagen die Pfadangabe zur Screaming Frog-Datenbank und wird im Arbeitsverzeichnis des Screaming Frogs in Deinem persönlichen Ordner abgelegt. Um die korrekte Pfadangabe zu Deinem Crawl zu finden, öffnen wir wieder unser Tool sfadmin.php in einem Terminal- / Command-Fenster:
- Aufruf des Tools
> php sfadmin.php - Aufruf der Liste aller Crawls
> getdata - Wähle nun den Crawl aus, auf dessen Daten Du zugreifen willst. Gebe die Nummer ein, die vor dem Crawl angezeigt wird. (z.B.)
> 68 - Die Meta-Daten des Crawls werden Dir jetzt im Detail angezeigt. Unter anderem auch der “Derby-Verbindungsstring”. Kopiere nun die komplette Zeichenkette beginnend mit “jdbc:derby” bis einschließlich “/sql” in die Zwischenablage
- Wechsel zu KNIME und füge die Zeichenkette in das Feld “Database URL” des Nodes ein.
- Schließe und bestätige die Konfiguration mit OK
Du solltest jetzt sehen, dass das Ausrufezeichen an unserem Node verschwunden ist. Die Konfiguration ist also vollständig.
Mit einem Klick auf “Execute” im Kontextmenü können wir prüfen, ob unsere Konfiguration erfolgreich war.
Daten aus dem Crawl abfragen
Nachdem wir nun eine Datenbankverbindung aufgebaut haben, können wir uns auch schon daran machen, die ersten Daten zu ermitteln. Dazu nutzen wir, bedingt durch den begrenzten SQL-Sprachschatz der Derby-Datenbank, ein Node vom Typ “DB Query Reader”:
Dieses Node verbinden wir mit unserem “DB Connector” wie folgt:
Wir müssen nun noch im DB Query Reader definieren, welche Daten wir aus dem Crawl auslesen möchten. Dazu öffnen wir die Konfiguration des DB Query Readers:
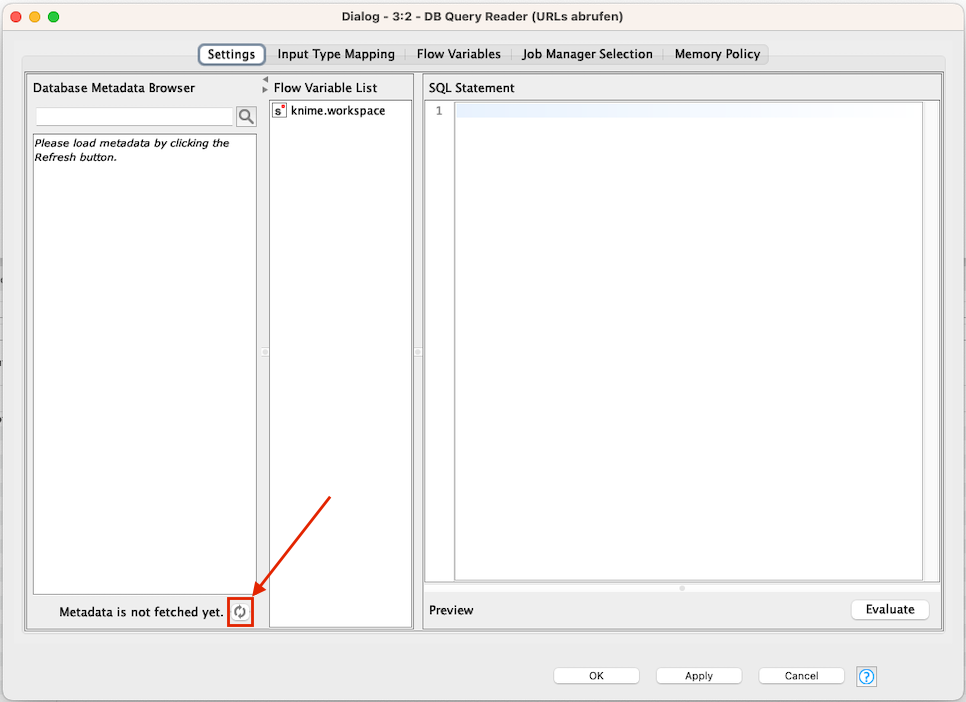
In dem linken Treeview (aktuell noch leer) werden Dir gleich alle verfügbaren Tabellen aus dem Screaming Frog Crawl angezeigt. Klicke dazu einfach auf das “Refresh”-Icon, welches ich in dem Screen markiert habe. Der Treeview wird sich aktualisieren (bei größeren Crawls kann dies auch schon einmal etwas Zeit in Anspruch nehmen):
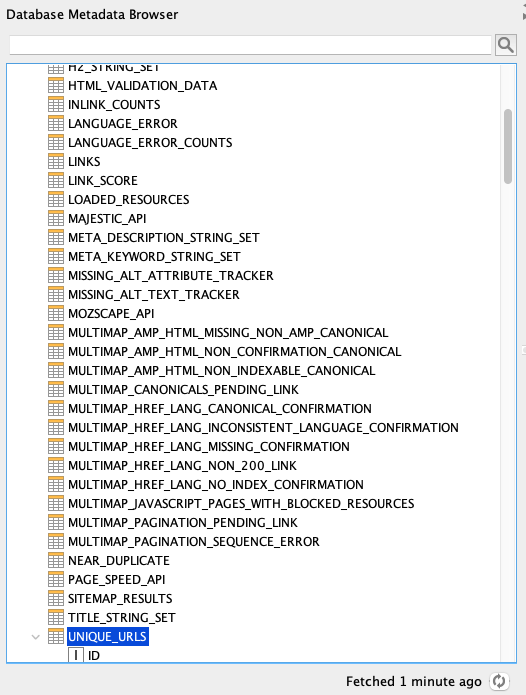
Wir sehen nun, welche Tabellen uns der Frog zur Verfügung stellt. Mit leichter (eingeschränkter) SQL-Magie können wir nun unsere Daten in KNIME überführen. Dazu möchten wir einmal alle URLs aus der Tabelle “UNIQUE_URLS” auslesen. In dem rechten Code-Feld geben wir also unser SQL-Kommando:
select * from "APP"."UNIQUE_URLS"
ein und bestätigen unsere Konfiguration mit OK. Die Konfiguration des DB Query Readers ist nun vollständig und wir können dieses jetzt ausführen:
Klicke dazu einfach im Kontextmenü des Nodes auf “Execute”. Im Node Monitor solltest Du nun die Daten aus Deinem Crawl sehen:
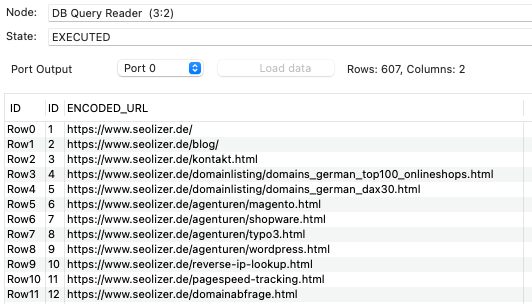
Wie gewohnt kannst Du nun in KNIME mit diesen Daten weiterarbeiten, sie manipulieren, aggregieren und die Ergebnisse in CSV-Dateien, direkt in Google Sheets oder anderen Datenbanken schreiben. Hierbei kannst Du verschiedene Aggregationsmethoden anwenden, um die Datenmengen zu analysieren und in einer Ausgabetabelle darzustellen.
Mögliche Fehlerquellen
“ERROR DB Connector 3:1 Execute failed: Datenbank '.../.ScreamingFrogSEOSpider/ProjectInstanceData/e595cdb9-5c6f-4445-aa96-2a0bcc20c706/results_bbcf4fbc-9d8f-45e8-9dc7-afceda9128f2/sql' konnte nicht mit dem Class Loader org.knime.database.driver.DBDriverRegistry$DriverClassLoader@382d4604 gestartet werden. Details können Sie der nächsten Ausnahme entnehmen.”

Das gilt jedoch auch in die andere Richtung: Hast Du den Crawl aktiv in KNIME in Verwendung, darf der Screaming Frog nicht auf seinen Crawl zugreifen.

In so einem Fall schließt Du KNIME oder nutzt im Kontextmenü des “DB Connector”-Nodes einfach den Punkt “Reset”, um die Datenbankverbindung wieder freizugeben.
Fazit
Gerade wenn es darum geht, Analyseverfahren zu standardisieren, bieten die Kombinationen aus Screaming Frog, KNIME und die Möglichkeit direkt mit den Daten arbeiten zu können klare Vorteile. Zwei Nachteile, mit denen wir leben müssen, sind die Performance und der begrenzte SQL-Sprachschatz (SQL-92) der Derby-Datenbank. Hier wären andere Datenbanksysteme klar im Vorteil und würden unsere Arbeit erheblich erleichtern. Jedoch bin ich froh, dass ich hier einen Weg gefunden habe, möglichst effektiv bestehende Softwarelösungen kombinieren zu können.
In meinem dritten und vorerst letzten Screaming Frog zu KNIME Artikel werden wir uns die ersten sinnvollen Auswertungen anschauen und näher auf die Datenstruktur der Screaming Frog Datenbank, den begrenzten Sprachschatz von SQL-92 und die Auswirkungen auf unsere Workflows eingehen. Dabei werden wir auch die Automatisierung von Analyseprozessen sowie die Bedeutung der Indexierbarkeit der analysierten Daten näher beleuchten.
Fehlt Dir in diesem Artikel etwas oder möchtest Du Deine Erkenntnisse teilen? Dann verbinde Dich doch über LinkedIn mit mir.
